TLS-induced headaches and a misbehaving firewall

Disclaimer. This post is based on real-life events, with real people, real communications and real institutions. All names in this post have been made up to respect the privacy of these very real entities. Some details have been altered for storytelling purposes, but the gist of this post remains intact. Any overlaps with the real world are incidental and not on purpose.
A wise, fat and lazy cat with orange fur once said “I hate Mondays”.
It was a Monday like any other. I got up in the morning, tired but functioning. I took a shower, toasted some bread, put jam on it, poured myself a glass of juice, had breakfast, brushed my teeth. At 7 in the morning, I sat in front of my desk staring at my work laptop. I checked my todos for the week, my e-mails, my private messages. It didn’t take long to find out that I’d be in for a ride.
Jett: “The Steelink service is down again.”
This was a message sent in a Slack channel that I’m in. And it wasn’t just sent at any time. It was sent the Friday before at 16:03 — three minutes precisely after I had left work to put my mind in weekend mode. How fun!
This Slack channel is a development hub for a nationwide research project. Many institutions all over the country are taking part in it and rely on the software that is developed as part of the project. The project lead, Jett, is the one who sent that message. A couple years back, they asked my superior to create a web service that could act as a database of all participants with a nice web interface to go along with it. It was supposed to be called Steelink.
It somehow turned into a Java-based monolith that occasionally responds with odd error messages and leaves even more confusing stacktraces on the server it runs on. The backend part of Steelink is something that I do not dare to touch to this day. But hey, at least the frontend looks nice!
So when I get a message that Steelink is not running — being the only person on our team who is at least slightly familiar with its oddities — I usually groan, roll my eyes and investigate. That Monday, it was no different.
Downtime to start the new year⌗
Working in research usually means taking whatever you can get your hands on — servers included. I have a couple of affiliations with other institutes and universities. So when it comes to hosting something like a web service for research, it’s easiest to just ask around who has a spare virtual server that is no longer in use.
I ended up with a slightly underpowered server hosted by Velback university. They were so kind to take care of basic server maintenance as long as I took care of getting the service up and running. The server has been behaving fine since the beginning. The service, as you might be able to guess, hasn’t.
At the start of 2023, I took a couple weeks off. During that time, it just so happened that the Steelink service had another outage. And since I was gone, no one with an idea of where to start looking was left, really. I didn’t even notice the downtime until I returned to work and read the many, many messages that had been sent during my absence.
Fortunately, since I wasn’t the only one who was taking time off work at the beginning of the year, no one really needed to access the Steelink service. Sure, getting it back online had high priority, but it wasn’t urgent, and I had a whole different backlog of things to clear before I could wrap my head around what happened while I was gone.
A few days passed and I decided to finally check up on the Steelink service. To my surprise, it was up and running as if nothing happened. So I decided to inform my project partners.
Me: “Steelink is working again.”
Jett: “Really? What happened?”
Me: “No clue…”
I eventually caught up with what happened in my absence. My supervisor — bless their heart — tried to troubleshoot Steelink and asked for assistance from Noel, the system admin at Velback university. Keep that name in mind, because they played a key role through all of this. They eventually escalated the issue to the responsible network admin. All three of them were passing mails back and forth to try and resolve the issue.
In the weeks prior to Steelink going down, several universities in Germany became involuntary targets of incredibly successful cyberattacks. They were forced to disconnect themselves from the internet for multiple days to reinstate compromised machines and for federal police to investigate. Other universities have been on high alert since these attacks, hardening their cybersecurity policies.
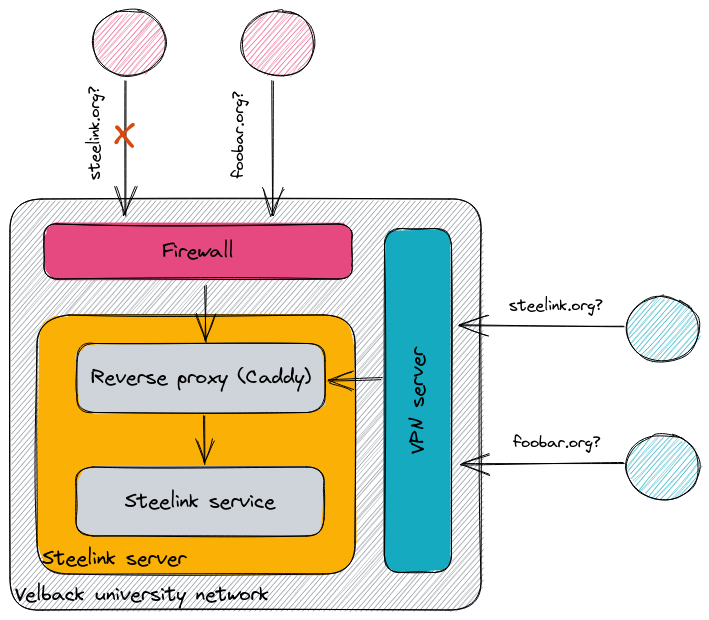
I never got an answer as to why Steelink suddenly started working again. But from the timeline of events, I thought that the network admin at Velback university must’ve been tinkering with the firewall which, for some odd reason, caused Steelink to become inaccessible. This is based on a very odd piece of information I was relayed.
The IT wizards at Velback were indeed working on improving firewall security. But in the process, all encrypted traffic to the Steelink server was supposedly forcibly downgraded to TLS 1.2 by the firewall. It appeared as if the reverse proxy that ran in front of Steelink service wasn’t capable of handling requests like these. As such, a special firewall rule was created for Steelink so that I could adjust the reverse proxy to only handle TLS 1.2 in order to play nice with the firewall. But I was also made aware that this rule would only persist for a couple days, since having exceptions in the firewall posed a security threat.
This explanation made no sense to me for a variety of reasons. First of all, I didn’t think firewalls changing TLS protocol versions on-the-fly were a thing. Second, TLS negotiation happens between a client and a server. Firewalls shouldn’t have the ability to negotiate TLS with anyone. Third, Caddy — the web server that I chose to put in front of the Steelink service to act as a reverse proxy and perform TLS termination — is very well capable of supporting both TLS 1.2 and 1.3.
If there was another proxy between the firewall and Caddy, then everything would’ve sounded a bit more plausible. However, since the firewall was explicity mentioned, I wasn’t sure what to think. So instead of complying with locking Caddy to TLS 1.2, I sat this grace period out.
Another brick in the wall⌗
“I should’ve listened,” I thought when I started investigating the issue. I typed in steelink.org in my browser to see if, maybe, the service had miraculously fixed itself again.
“Connection reset.”
I sighed. It was not a fluke. But still, the error seemed odd to me. I was used to requests timing out or Steelink responding with obscure error messages, but this was new. My hope for a quick fix was dwindling by the seconds. So I logged into the Velback University VPN to be able to SSH into the Steelink server. When I did that, my browser automatically refreshed.
And there it was: the Steelink interface, as if nothing ever happened! The connection was secured with TLS 1.3 even. So the service was up, but it probably couldn’t be reached from outside the university network. I double-checked by SSH’ing into the server and checking all running processes. And indeed, the Steelink service was running smoothly. The logs, as cluttered as they were, didn’t reveal any malfunctions in the past couple days too.
Something weird was going on. I was pretty sure that my traffic wasn’t being routed through the university firewall while I was connected to the Steelink service via the VPN. So surely there had to be something up with the firewall if I was unable to access Steelink from outside the university network.
TLS lingered on my mind, so I used the OpenSSL test client to diagnose the issue some more.
Running openssl s_client -connect 123.45.67.89:443 -servername steelink.org attempts a TLS handshake with the web server located at 123.45.67.89 and explicitly asks for a certificate for steelink.org.
I ran this command against the Steelink server IP, once with and once without a VPN connection.
To no surprise, the TLS handshake only worked while I was connected to the university VPN.
Eventually I caved in. I adjusted Caddy to offer nothing but TLS 1.2 and retried the same command, once with and once without a VPN connection. Again, the TLS handshake only succeeded with a VPN connection. However, this told me that TLS 1.2 wasn’t the solution. I configured the reverse proxy as I was told to do and it still didn’t work.
Now this was already a breakthrough in my opinion, but I wanted more.
So I started changing another parameter.
I’ve no idea what got into me at that point, but I altered the TLS test client command to run with -servername foobar.org instead.
And to my utter astonishment, the TLS handshake suddenly worked even when I didn’t have an active VPN connection!
Sure, I didn’t get any valid TLS certificates since Caddy knows only to cater to steelink.org, but it still worked.
With concrete proof that the requested server name is most likely to trigger the issue, I compiled all my findings and logs and sent them off to Noel. Not even half an hour later, I get a call.
Negotiating negotiations⌗
On the phone, Noel reassured me that, more or less, they had already come to the same conclusion. Still, they suggested to lock down the TLS versions offered by the reverse proxy. After saying that I had already done that, I was asked to try TLS 1.1 and 1.0 instead.
I shook my head. Then I remembered that they wouldn’t be able to see my physical disagreement through the phone. I argued that TLS 1.1 and 1.0 were dead for good and that this couldn’t possibly be the solution to this problem. Noel agreed, but also admitted that they weren’t familiar with TLS on a protocol level. This step was supposed to help the network admin diagnose the issue further. After being told that this would definitely not remain a permanent solution, I reluctantly agreed.
I knew I relied on the cooperation of the Velback IT staff. Pushing back on suggestions that, to my understanding, were ridiculous, didn’t help me nor them. I might’ve be able to make fair assumptions about their infrastructure, but I was also aware that they were just that: assumptions. So the next step was to figure out how to get deprecated TLS versions onto the server.
I mentioned Caddy as my web server of choice before. I love it for its easy configuration, even if it may not be nearly as performant as most other web servers out there. But Caddy was not made to debug TLS connections in this very odd edge case. Caddy doesn’t support TLS versions 1.1 and earlier for security reasons. You can’t even force it to do that with some hidden command line argument or something like that. It’s simply not implemented.
Since none of our project partners were able to access Steelink anyway, I decided to stop the service and install a fresh nginx instance on the server instead.
Fortunately, nginx is highly configurable and even allows TLS 1.0 and 1.1, but not without jumping through some hoops too.
The secret sauce is to add the pseudocipher @SECLEVEL=1 to the ssl_ciphers key in the nginx web server configuration, as pointed out in a response on Ask Ubuntu.
A lower security level allows the usage of weaker cipher suites — a cryptographic nightmare, but an unfortunate necessity given the circumstances.
http {
server {
listen 443 ssl;
server_name steelink.org;
ssl_certificate steelink.org.crt;
ssl_certificate_key steelink.org.key;
# Evil lurks beneath this line.
ssl_protocols TLSv1 TLSv1.1 TLSv1.2 TLSv1.3;
ssl_ciphers "EECDH+AESGCM:EDH+AESGCM:AES256+EECDH:AES256+EDH:@SECLEVEL=1";
}
}
I know this shouldn’t bear mentioning in a blog like mine which is more catered towards the tech-savvy, but I will say it regardless. Do not, under any circumstances, instruct a web server to offer TLS 1.1 or earlier in a production setting. Only do this if you know exactly what you are doing and you’re hyper-aware of the possible consequences. These versions have serious security issues and are therefore deprecated for a reason. Understood? Understood.
After nginx was up and running with the infamous default “Welcome to nginx!” page, now offering TLS versions 1 through 1.3, I tried my luck with the OpenSSL test client again, only to observe the same pattern as before. When I was not connected to the university VPN, I found that the TLS handshake worked when I requested a certificate for foobar.org from the Steelink server, but not for steelink.org. This worked no matter the TLS version.
I called Noel to let them know I configured the reverse proxy as they asked, and that I was sure the TLS version had nothing to do with the problem at hand. In return, they assured me that they’d nag the network admin to look into this issue again. I was also told that the info about the alleged TLS downgrade by the firewall came from the network admin who ran a TCP dump on the Steelink server during the previous service outage. I thanked Noel for their endless patience and we remained on stand-by until there were new findings to be shared.
One hand breaks the other⌗
There was nothing that I could do at that point but wait. I had exhausted all my options. So I did some more research to come up with a more reasonable explanation as to what was going on. This was the first time that I read into how the TLS protocol actually works.
At the beginning of every TLS handshake, the client sends a ClientHello message where it includes information about the TLS version and cipher suites it supports. There exists a TLS protocol extension called Server Name Indication (SNI). SNI allows a client to specify the name of the server to which it would like to establish a secure connection. Since a ClientHello message is sent in plain text, a firewall standing between a client and server has the possibility to inspect it.
To me, it made more sense that the Velback firewall might reject TLS handshakes with a steelink.org SNI contained within. The firewall would then reset the TCP connection, explaining the error message in my browser when I tried to access Steelink from outside the university network. This doesn’t explain why the firewall would do such a thing, but it seemed a lot more plausible to me given what I observed.
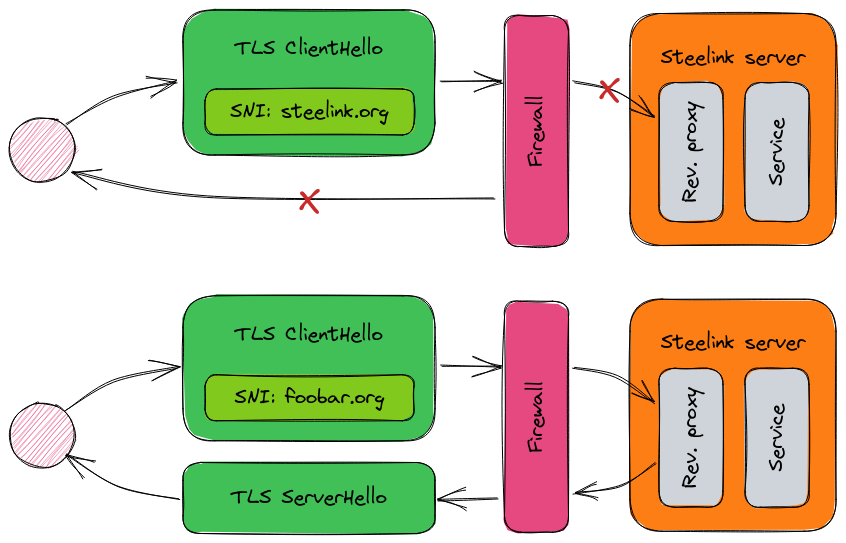
It is worth noting that SNI is only a thing starting with TLS 1.2. So if you request certificates from a server using TLS 1.1 or earlier, you will actually get all available certificates on the server back, even if they are unrelated to your target domain.
But if SNI is not a thing with TLS 1.1 and earlier, then how come the TLS handshake was still reset in my testing? I have no definitive answer for that, but I assume the firewall could look into the subject line of the certificates returned by the service where it’d find steelink.org, blocking the outbound response.
I also looked around in the Steelink server some more to find any valuable traces. As luck would have it, I found a TCP dump created by the network admin. So I copied it onto my work laptop and inspected it with Wireshark. And as I looked at it, I was growing more confident in my hypothesis.
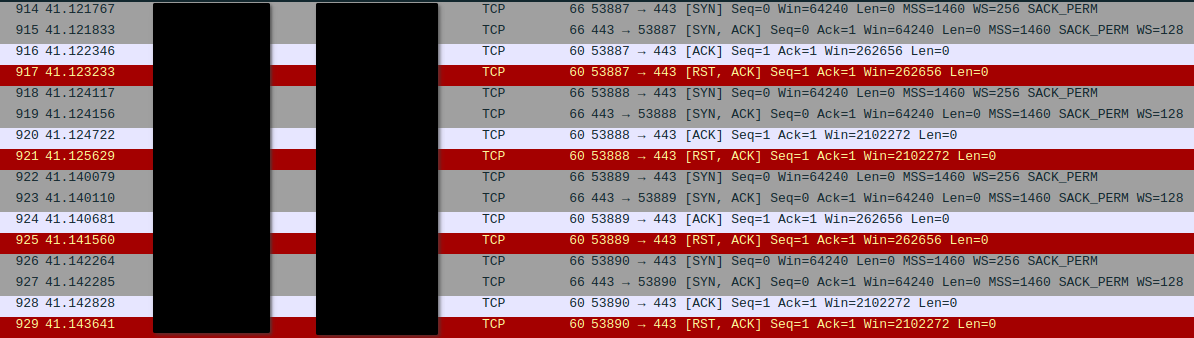
I could see the TCP handshake between what I presumed to be the firewall and the reverse proxy. And all of a sudden, the TCP connection was reset by the firewall. The rest of the TCP dump looked like the usual background noise you’d see on a large network.
This wasn’t hard proof by any means. I found one TCP dump that confirmed my suspicions. The network admin might’ve done a lot more TCP dumps and left only the most recent one on the server. But I’d be lying if I said I wasn’t proud of myself for having gone the extra mile to find a decent explanation for what was going on. Still, I was waiting to hear back from Noel …
It all PANs out in the end⌗
I waited a whole week without hearing back from them. The project partners were getting more impatient with the lack of news, but I said I wouldn’t give out unconfirmed information and that I was getting just as impatient. I called up Noel again and asked what the current state was. And as expected, they told me that the network admin hadn’t come back to report anything insightful yet.
In fact, Noel admitted to me that they weren’t sure if the network admin looked into the issue at all in the past week. Once again, I was reassured that they’d keep nagging the network admin to take a look. And once again, I thanked them for their ongoing support.
We talked for half an hour about the state at the time. They told me that the whole IT staff had been running around with their heads on fire ever since the recent cyberattacks on national universities. There were lots of services to take care of, lots of holes to patch, and lots of uncomfortable decisions to be done in favor of security, even if it came at the cost of user-friendliness.
All I wanted was to have this issue taken care of. And even though I was about 90% confident in my hypothesis, I couldn’t help but feel bad for them. From what I knew, their firewall now ran at the highest security level. No exceptions. They were probably more likely to look into troubleshooting options that didn’t involve making any modifications to the firewall. At least I would’ve done the same in their shoes.
Suddenly, the origins of the initial TCP downgrade story made a bit more sense to me. I was still not convinced of course. After all, I still held onto the proof that this couldn’t have possibly been the root cause. But I felt like the idea came from an IT department that had been going through hell and back in the past month, and that had other priorities than to look into a really obscure issue in a service that they weren’t even really affiliated with. This perspective helped me calm down a fair bit.
But nothing — absolutely nothing — could’ve prepared me for the call that I received the very next day.
Noel: “We found the issue.”
Me: “Oh really?”
Noel: “Palo Alto.”
Me: “What?”
Noel: “The company.”
Me: “Yes but … explain?”
They then forwarded an e-mail to me from the network admin. The attached screenshot left me speechless for a good minute.
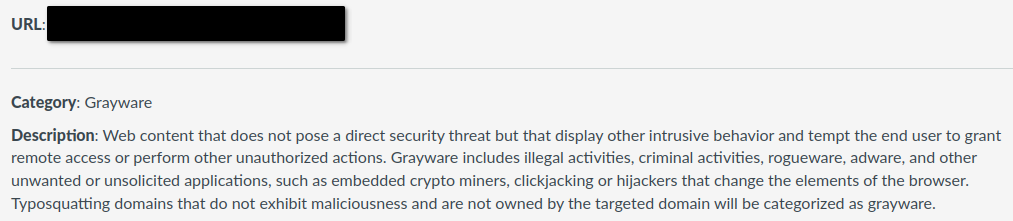
The Velback firewall is a Palo Alto Networks (PAN) product. PAN has a URL filtering database called PAN-DB. Its purpose is to provide a reliable resource to identify malicious URLs. And it just so happened that steelink.org was mistakenly classified as grayware.
So my theory was correct, but TLS handshakes with a steelink.org SNI were being blocked through no fault of the IT staff. Instead, their firewall looked up steelink.org in PAN-DB, found that it was flagged as malicious and therefore rejected the handshake, resetting the connection.
I was happy and disappointed at the same time: happy because the root cause of the issue had finally been found, and disappointed because the issue had to be escalated a lot further to be resolved. We agreed that I’d take this issue into my own hands again, and that I’d let them know if I achieved something.
Fortunately, PAN has a convenient link below a URL’s classification to request a change. My hopes weren’t high, because why would a multi-billion dollar company act on the request of a single person in a medium-sized research project? Still, there was no point in not trying, so I submitted a change request.
Within five hours, they accepted my request. Five hours! This was a lot faster than I could’ve ever imagined. I opened my browser and typed in steelink.org … and then I remembered nginx was still running on the server. So I ended up seeing the “Welcome to nginx!” page, but I’ve never been happier to see a naked, publicly-accessible nginx web server with a dodgy TLS configuration. I SSH’d into the server, stopped nginx, started Steelink, waited a minute and refreshed my browser.
I gave Noel a final call to tell that everything was in working order again. I pinged everyone in the Slack server to say that Steelink had risen from the ashes. I felt the weight of an issue that I couldn’t have resolved on my own being lifted off my shoulders.
Jett: “WTF?”
Me: “How do you think I felt when I saw that?”
Jett: “This is the most random sh** I ever heard.”
So why was Steelink classified as grayware? I’m sure that no human looked at our site and thought “hm, yes, this has to be work of someone trying to deceive their users”. Maybe someone owns a domain similar to steelink.org and thought we were trying to draw traffic away from their service. Or maybe some artificial intelligence at PAN mistakenly blacklisted our domain during some routine database maintenance task. I don’t know, nor do I really care at this point. All that matters to me is that things are running smoothly again … well, until the next Steelink outage, that is.
There are a few more closing remarks that I’d like to get off my chest. First, we all make mistakes. Sure, the issue could’ve been resolved on day one, but hindsight is always 20/20. I don’t mean to push the blame on any person or entity, because I sure don’t need to put fuel to an already well-lit bonfire. All I want to show with this post are the things that I learned along the way of getting this issue fixed.
Second, this is not an endorsement of or advertisement for PAN. I have never used any of their products, nor am I familiar with them. All I can say is that I was impressed by the fast response time to my reclassification request. So good job, PAN. You earned yourself a cookie, but only if you click “Accept All” on the cookie banner first.